요즘은 사회 전반적으로 특정 이벤트나 이슈가 생길 때마다 사람들이 재치있는 아이디어로 국내에선 짤, 해외에선 밈(meme)이라고 불리우는 패러디 이미지가 많이 퍼지고 있습니다.
보통은 이런 이미지를 그림판이나 포토샵 등을 이용해서 만드는데 인기있는 짤의 경우 보통 대사 위치가 정해져있는 경우가 많기 때문에 별도의 이미지 도구 없이 html과 javascript를 이용하여 간단하게 짤 이미지를 생성할 수 있는 웹페이지를 한번 만들어 보겠습니다.
가급적 관련 기술에 대해서 모르시는 분들도 어느정도 이해하고 읽을 수 있도록 내용을 풀어서 작성하였습니다. 오히려 복잡할 수도 있는데요 만약 이해하기 어려우시면 html이나 css, javascript에 대한 일부 기초 지식을 참고하시길 바랍니다.
이미지 선정

이 이미지는 for the better, right? 라는 짤(밈)으로 커뮤니티에서 자주 볼 수 있는 스타워즈의 한장면 입니다.
파드메의 해맑은 표정, 당황하는 표정, 아나킨의 무표정 장면을 연결해서 만들어진 이미지로 각종 패러디 이미지로 만들어지고 있습니다.

기본 레이아웃 설계
패러디되는 짤을 보면 보통 파드메 영역에만 대사를 넣거나 또는 상단 부분에는 역할 내지 이름에 해당하는 내용을 넣기도 하기 때문에 이미지를 각 장면별로 구분하여 네등분 한다고 할 때 각 장면마다 상단, 하단에 각각 텍스트를 입력 받는 형태를 가정했습니다.

HTML 문서 작성
HTML 포맷은 웹페이지에서 사용되는 문서 포맷중 하나 입니다. 크게 head와 body 영역으로 구분되어있고 head는 보통 문서의 정보 및 외부 참조 스크립트, 스타일 등이 포함되고 body는 실제 표시할 컨텐츠나 사용자 스크립트 등이 포함됩니다. 여기서는 자세한 내용은 다루지 않을 예정이니 기초 정보는 https://www.w3schools.com/html/ 같은 사이트를 참조하시길 바랍니다.
레이아웃
|
|
위 코드를 보면 body 영역에 div(ision) 라는 태그 이름을 가진 컨테이너(이하 영역)가 다수의 쌍으로 구성되어 있는 것을 볼 수 있습니다. 해당 영역들은 실제 컨텐츠가 저장되는 구역을 지정해놓은 것이고, 쌍으로 이루어진 영역내에 들여쓰기된 영역은 하위 영역으로 위치한 것으로 볼 수 있습니다.
그리고 각 영역은 id 또는 class 속성(attribute) 부분에 사용자 임의의 문구로 지정이 되어있는데, 이는 영역을 구분하기 위한 것이고 일반적으로 id 속성 값은 단일 속성 값으로 단독 구분/선택이 필요할 때 사용되고, class 속성 값은 복수의 값을 가질 수 있으며 복수 구분/선택이 필요할 때 사용됩니다.
위 코드에서 계층 관계를 그리면 다음 그림과 같은 형태가 되는데 포함하는 영역과 포함된 영역은 각각 상위/하위 또는 부보/자식 관계에 해당합니다. 이후부터는 해당 명칭으로 계층 구분을 하도록 하겠습니다.
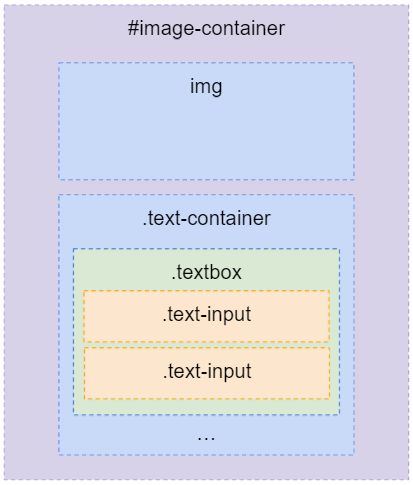
마지막으로 text-input 영역의 경우 contenteditable라는 속성이 true로 지정되어 있는데, 이렇게 지정하는 경우에는 input 태그처럼 일반 div를 사용자 입력 이 가능한 상태로 만들어 줍니다.
이렇게 작성된 html 코드를 문서로 저장하고 브라우져에서 읽어오면 다음과 같은 화면으로 표시가 됩니다.

이미지 밑에 검은 박스는 contenteditable 영역을 마우스로 클릭하여 텍스트 입력 상태로 전환된 상태이고 현재 상태에서는 이미지의 각 장면에서 텍스트 입력이나 표시가 불가한 상태입니다. 이미지 하단에서만 텍스트 입력이 되는 상태이므로 원래 계획했던 레이아웃을 만들기 위해서는 div 영역에 대한 스타일을 지정해주는 작업이 필요합니다.
스타일은 CSS(Cascading Style Sheets)1라는 스타일 언어로 각 영역의 디자인 요소를 지정 할 수 있는데 해당 언어는 영역 태그 내 style 속성이나 또는 head 내에 style 태그를 이용하거나 css 확장자를 가진 별도의 파일을 생성하고 연결하여 정의할 수 있습니다.
여기서는 head 내의 style 영역에서 스타일을 지정하겠습니다.
스타일 지정
|
|
CSS에서는 태그 이름(img, input, div 등등)이나 id, class 같은 속성 값 또는 tag의 상태에 따라 영역을 선택하고 원하는 디자인 요소를 적용할 수 있습니다. 참고로 몇몇 스타일 속성들은 영역의 계층간(부모/자식) 상호 영향을 받습니다.
그리고 id 속성 앞에 #(sharp)을, class 속성 앞에 .(dot)을 붙임으로써 해당 속성을 가진 영역 선택이 가능하므로 #과 .을 이용하여 영역별로 디자인 속성을 각각 적용 할 수 있습니다.
먼저 이미지 컨테이너(#image-cotainer)는 밈 이미지 크기(768 x 768)에 맞게 가로세로를 지정하였습니다. 사이즈를 별도로 지정하지 않아도 내부의 컨텐츠에 맞추어 자동 크기가 지정되기도 하지만 자식 영역의 스타일 속성에 따라 달라질 수도 있기 때문에 이미지 사이즈에 맞추었습니다.
다음은 이미지 컨테이너 하위의 텍스트 박스 컨테이너(.textbox-container)의 position 속성을 absolute로 지정 하였습니다, 이렇게 정의하면 부모 또는 문서의 최좌측 상단의 좌표를 기준으로, 독립적으로 절대적인 위치(좌표)에 영역을 표시할 수 있습니다. 그러나 이미지 컨테이너 position 속성이 relative 이기 때문에 텍스트 박스 컨테이너는 자신의 좌표 기준점을 이미지 컨테이너를 기준으로 삼게 됩니다. 그리고 top, left 절대 좌표 속성 값이 모두 0이기 때문에 텍스트 박스 컨테이너는 이미지 컨테이너 내부를 기준으로 좌상단 좌표(0, 0)에 위치하게 될 것 입니다.
여기서 이미지 컨테이너와 img 태그(이미지)는 모두 동일한 사이즈에 img는 별도의 포지션 지정이 없으므로 결론적으로는 이미지 컨테이너, img, 텍스트 박스 컨테이너는 모두 동일한 좌표에 놓여있게 됩니다.
그리고 텍스트 박스 컨테이너의 width, height 속성 값이 100% 로, 가로 세로 크기 속성의 퍼센트 값은 부모 영역에 영향을 받으므로 하므로 최종적으로 세 영역은 동일한 크기 동일한 좌표에 표시가 될 것 입니다.
텍스트 박스 컨테이너 속에 텍스트 박스(.textbox)는 가로 세로 50% 로서 앞서 언급한 특성으로 인해 텍스트 컨테이너(곧 이미지 컨테이너)의 절반 사이즈(384 x 384)로 계산되어 적용되며, 텍스트 컨테이너의 display 속성 값이 flex이고 flex-wrap 속성 값이 wrap임 따라 내부에 있는 자식 영역(텍스트박스)들은 세로가 아닌 가로로 늘어진 형태로 놓일 수 있게 됩니다.
다만 텍스트 박스 영역은 4개이고 3개 이상부터는 부모 영역의 가로 크기 넘어서는데, 정의된 스타일 속성상 가로 크기를 넘어서 표시가 될 수 없으므로 세번째, 네번째 텍스트 박스는 가로로 표시되지 못하고 하단으로 밀려 내려오게 되서 4등분 된 것처럼 보이게 됩니다.
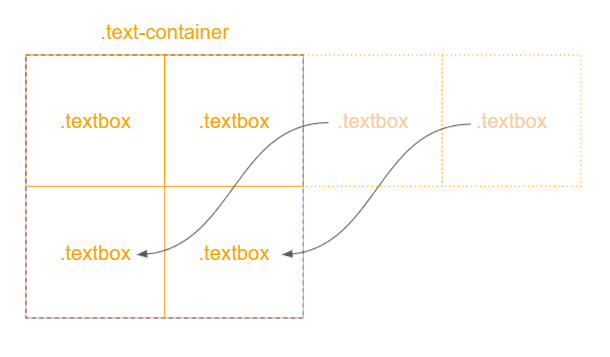
텍스트 박스 또한 dispaly 속성 값이 flex 이지만 flex-direction 속성 값이 column 이므로 자식 영역인 텍스트 인풋(.text-input)은 가로가 아닌 세로로 상단에서부터 순차적으로 나열됩니다. 그러나 justify-content 속성 값이 space-between 이므로 자식 영역들은 인접하지 못하고 분리가 되는데, 이 속성으로 인하여 두 개의 텍스트 인풋은 텍스트 박스 내부에서 상단과 하단 양 끝에 위치하게 됩니다.
(flex 속성은 https://developer.mozilla.org/ko/docs/Web/CSS/flex 링크에서 더 자세한 내용을 확인할 수 있습니다.)
마지막으로 .text-input:empty:after 선택자에 content 속성이 지정되어 있습니다. 이 선택자는 텍스트 인풋 영역 내부가 비어있는(:empty) 조건에만 발생하는 스타일 입니다. :after2와 같은 선택자는 일명 의사(pseudo, 가짜 또는 가상의) 요소(element)로서 직접 html 태그를 작성하지 않고도 컨텐츠를 생성하여 추가해주는 역할을 합니다.
그래서 .text-input:empty:after 선택자를 풀어서 쓰면 다음과 같습니다.
- class에 text-input 값을 가진 빈 영역 내 ‘텍스트 입력’이라는 content를 가진 임의의 영역을 표시
이렇게 스타일을 적용한 뒤 저장하고 다시 불러오면 다음 화면과 같이 원래 의도했던 디자인 레이아웃이 적용된 것을 확인 할 수 있고 해당 위치에 텍스트 입력이 가능하게 됩니다.

스크립트 작성
사전 준비
기본적인 레이아웃이 완성되었지만 현재 상태에서는 이미지와 텍스트를 각각 표시만 가능한 상태이므로 이미지와 텍스트를 합쳐서 하나의 이미지로 만드는 작업이 필요합니다. 이러한 작업은 html과 css만으로는 어렵기 때문에 자바스크립트를 작성해서 기능을 구현할 것 입니다.
마침 이러한 동작을 쉽게 구현할 수 있게 해주는 html2canvas3라는 라이브러리가 있습니다. html2canvas는 html내 특정 영역을 선택하여 화면에 표시된 모양 그대로 이미지화(캡쳐) 시킬 수 있도록 도와줍니다.
이 라이브러리를 사용하기 위해서 head 영역에 script 태그를 이용하여 라이브러리를 등록합니다.
|
|
이처럼 등록하면 문서를 읽어올 때 해당 라이브러리를 불러올 것 입니다. 하지만 라이브러리를 등록했다고 해서 이미지 변환이 자동으로 되는 것은 아니므로 제어를 위한 이미지 캡쳐 버튼, 작성된 텍스트를 쉽게 초기화 하기 위한 텍스트 지우기 버튼 마지막으로 캡쳐된 결과를 표시할 영역을 추가합니다.
그리고 해당 영역들에 대한 스타일도 지정을 해야 하는데 결과 이미지 영역은 평소엔 보이지 않다가 캡쳐 동작 이후에만 화면 정중앙에 팝업 형태로 표시할 예정이므로 display 속성을 none으로 하여 기본적으로 보이지 않도록 합니다.
앞서 정의했던 .text-input:empty:after 선택자를 #image-container:not(.placeholder–hidden) .text-input:empty:after 로 변경해줍니다. 이에 대한 설명은 하단에 설명하겠습니다.
|
|
스크립트
UI 요소가 마련되었으므로 실제로 동작 수행을 위해서 스크립트를 작성합니다. body 하단 영역에 script를 태그를 추가해줍니다. 해당 스크립트는 문서가 모두 로드 되면 호출이 될 것입니다.
|
|
자바스크립트를 전혀 모르시는 분들이 있을 수 있으므로 코드 보다는 동작 위주로 설명을 하겠습니다. 먼저 doument.getElementById 를 이용해서 스크립트에서 직접 속성 조작이 필요한 영역(element)을 선택해줍니다.
그리고 각 버튼은 사용자가 클릭 시 동작해야 하므로 onlick에 이벤트를 설정합니다.
먼저 캡쳐 버튼(btn-capture)의 이벤트 동작은 결과 이미지를 표시할 영역(팝업 다이얼로그) display 속성을 none 에서 flex로 변경해줍니다. html에서는 css 조작만으로도 새로고침이나 특별한 작업 없이도 새 스타일 적용이 가능하기 때문에 이전에 표시가 되지 않던 팝업 화면이 보이게 됩니다.
그리고 이미지 컨테이너 class에 placeholder–hidden 값을 추가 해주는데 이 것을 추가하는 이유는 앞서 텍스트 인풋에 아무런 내용도 없을 때 표시해주던 메시지를 숨김처리 하기 위함 입니다. 이 동작을 수행하지 않으면 텍스트를 입력하지 않은 영역에서는 텍스트 입력이라는 글자가 같이 캡쳐가 됩니다.
그래서 캡쳐 직전에 일시적으로 숨김처리하고 캡쳐 이후에 이미지 컨테이너 class에서 placeholder–hidden 값을 제거해서 다시 원래 상태로 되돌려 놓습니다.
그 다음엔 html2canvas 라이브러리로 이미지 컨테이너 영역을 캡쳐합니다. 이때 반환되는 canvas element를 결과 이미지를 표시할 다이얼로그 컨텐트 영역에 추가하면 캡쳐된 이미지를 확인 할 수 있습니다.
닫기 버튼은 아까 생성하여 추가한 canvas를 지우고 다이얼로그 영역을 숨김처리 합니다. 텍스트 지우기 버튼은 getElementsByClassName를 이용하여 모든 텍스트 인풋 영역들을 선택해서 내부 컨텐츠를 공백 문자로 변경하여 초기화 시킵니다.
결과
자 그럼 이렇게 작성된 코드를 저장해서 다시 불러오면 다음과 같이 쉽게 짤을 생성할 수 있는 페이지가 완성되었습니다. 캡쳐된 이미지는 마우스 오른 클릭 메뉴를 통해 저장 또는 복사가 가능합니다.
만들어진 페이지는 다음 주소에서 사용해보실 수 있습니다.

그리고 최근 인기가 있는 김연경 선수 밈이나 집이 무너졌어요 슬펐어요 (그것이 알고싶다 싱크홀 편) 밈도 추가된 페이지 링크도 공유드립니다.

추가 정보
아까 CSS 파일이 별도로 작성하여 연결이 가능하지만 head 내에 직접 삽입도 가능했습니다. 이미지 파일도 Base64라는 문자열 데이터로 변환하면 마찬가지로 html에 삽입할 수 있습니다.
물론 이렇게 하는 경우 매우 긴 문자로 문서개 가득채워지기 때문에 복잡하지만 html 파일 하나로만 작성이 가능하기 때문에 변환 및 적용 방법을 알려드리겠습니다.
먼저 이미지 변환을 위해 https://elmah.io/tools/base64-image-encoder/ 같은 사이트에 이미지를 업로드 하여 변환을 합니다.
잠시 기다리면 결과 값이 나오는데 중간에 HTML usage 를 보시면
img src=“data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEAYABgAAD/4….
와 같이 매우 긴 문자열로 변환된 값을 보실 수 있습니다. 이 태그를 img 태그 대신 사용하시면 별도로 이미지 파일없이 html 파일 하나만으로 결과물을 만들 수 있습니다.